Microservices With Event Sourcing And Redis
For the last year or so, the development team at Learning.com has been working to move toward a microservices based architecture. This will allow us to scale up beyond what our current monolithic architecture can handle and allow us to deliver our award winning educational content to more students in more ways. In this blog post I will be talking about how we share data across microservices using an event-driven architecture and how we implement that using the Event Sourcing pattern and Redis.
Communication between microservices
One of the fundamental tenets of the microservices architectural pattern is the idea of “data sovereignty per microservice”. That is, each service owns and controls it’s own domain data and logic. They approximate a Bounded Context in the lexicon of Domain Driven Design (DDD). Each service has it’s own datastore and services do not reach directly into each other’s private data stores to update their own state or retrieve data for display. This allows services to stay highly decoupled, independently scalable, and independently deployable. The challenge with this is determining how services communicate across boundaries. In a naive design like the one below, services can communicate with each other through their public HTTP API, but this can lead to a host of possible problems.
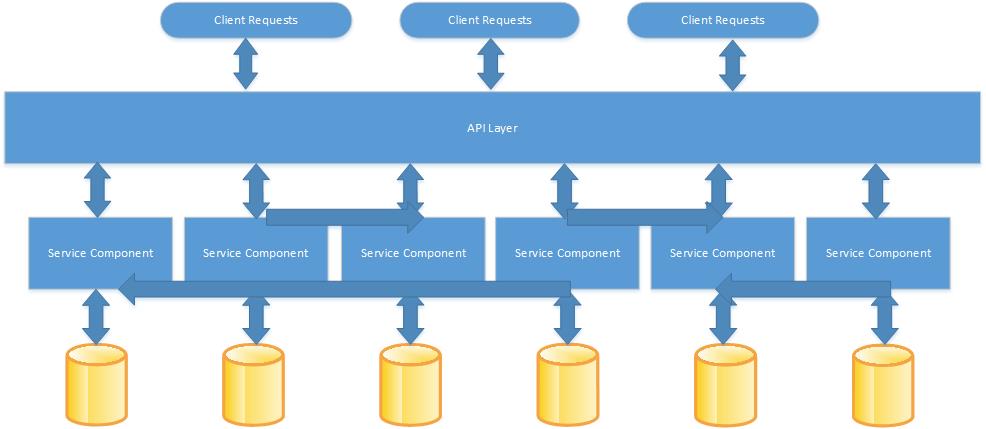
For example, consider an order management system where you might have an Order service and a Customer service. When an order is created in the Order service, the Customer service needs to update it’s data store to associate the order with a customer. In this scenario, the Order service could directly update the Customer service through it’s public HTTP API. However, this creates tight coupling between the two services as now the Order service must know about the Customer service. If other services that need to be updated about an order are added, the Order service quickly builds up a complicated set of dependencies and logic to manage them.
Such a design can also introduce performance problems as the UI must wait for multiple HTTP calls to be made between all of the services to update their data. Finally, it leads to data consistency issues in making sure that all data stores get properly updated. In such a distributed system there is no way of guaranteeing that updates to all the services are performed atomically. According to the CAP theorem, no distributed system is safe from network failures and therefore, we must choose between application availability or data consistency when network failures occur. What that means for this example is that there may be a situation where one of the services is down, or the network connection between services is down, and therefore data cannot be updated. In this scenario, either the whole system will have to fail and give the user an error, or the data will be end up in an inconsistent state. One way to address these issues, and the solution that we embraced at Learning.com, is to use an event driven architecture instead of direct communication between services wherever possible.
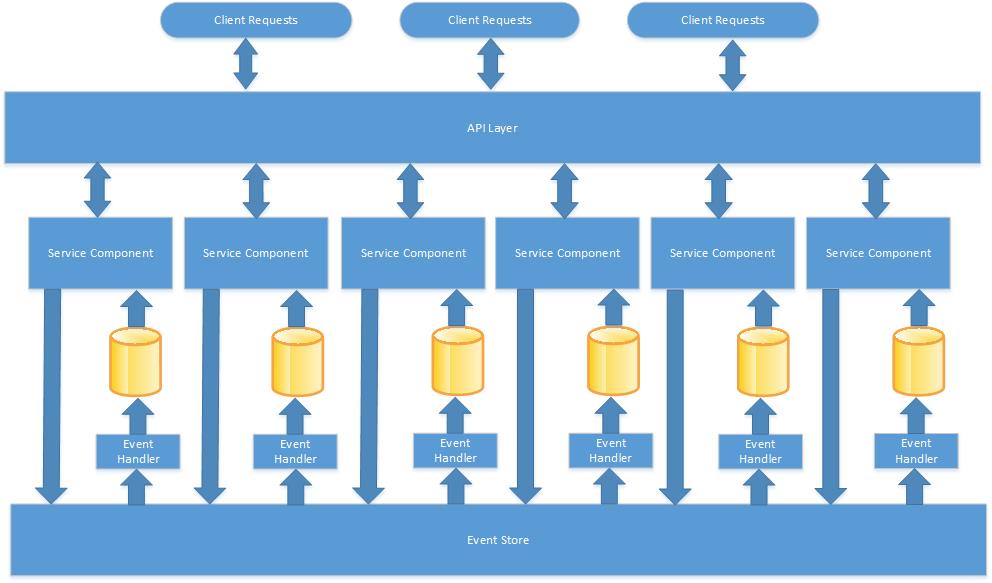
In an event driven system, instead of a service sending a notification directly to other services that data has changed, an event is published that other services can subscribe to and update their own internal state in response. This allows for greater decoupling as services do not need to know about each other, they only need to know about events. In the example above, instead of sending data directly to the Customer service through it’s HTTP API, the Order service would instead publish an event when an order is created that the Customer service could subscribe to and update it’s internal state based on the data contained in the event. It is not necessary for the Order service to know anything about the Customer service in this scenario. In fact any number of services can subscribe to the Order event without the need to modify the Order service at all.
Event Sourcing
There are many ways to implement an event based architecture, but the pattern we chose is known as Event Sourcing. Event Sourcing is defined in the excellent architecture literature published by Microsoft as:
“Instead of storing just the current state of the data in a domain, use an append-only store to record the full series of actions taken on that data. The store acts as the system of record and can be used to materialize the domain objects. This can simplify tasks in complex domains, by avoiding the need to synchronize the data model and the business domain, while improving performance, scalability, and responsiveness. It can also provide consistency for transactional data, and maintain full audit trails and history that can enable compensating actions.”
Event sourcing makes use of an append-only “Event Store” that stores all of the events that have been performed on a domain object to get it to it’s current state. The Event Store is also responsible for publishing events that other services can subscribe to in order to create different materialized views for different purposes. Event Sourcing solves the problem of atomic operations and data consistency by providing the Event Store as the single source of record. Since it is only ever written to once for each event, updates are inherently atomic. This also allows for more responsive and performant applications because the UI does not need to wait for multiple data sources to be updated before continuing. All that has to happen is the write to the Event Store with all other event processing happening in the background while the UI continues. It allows for any number of subscribers to events to produce any number of materialized views without having any impact on the performance of the UI. It also allows for maximum agility because it is easy to consume events and replay past events to create other views of the data in the future that cannot be anticipated now.
Redis Event Store
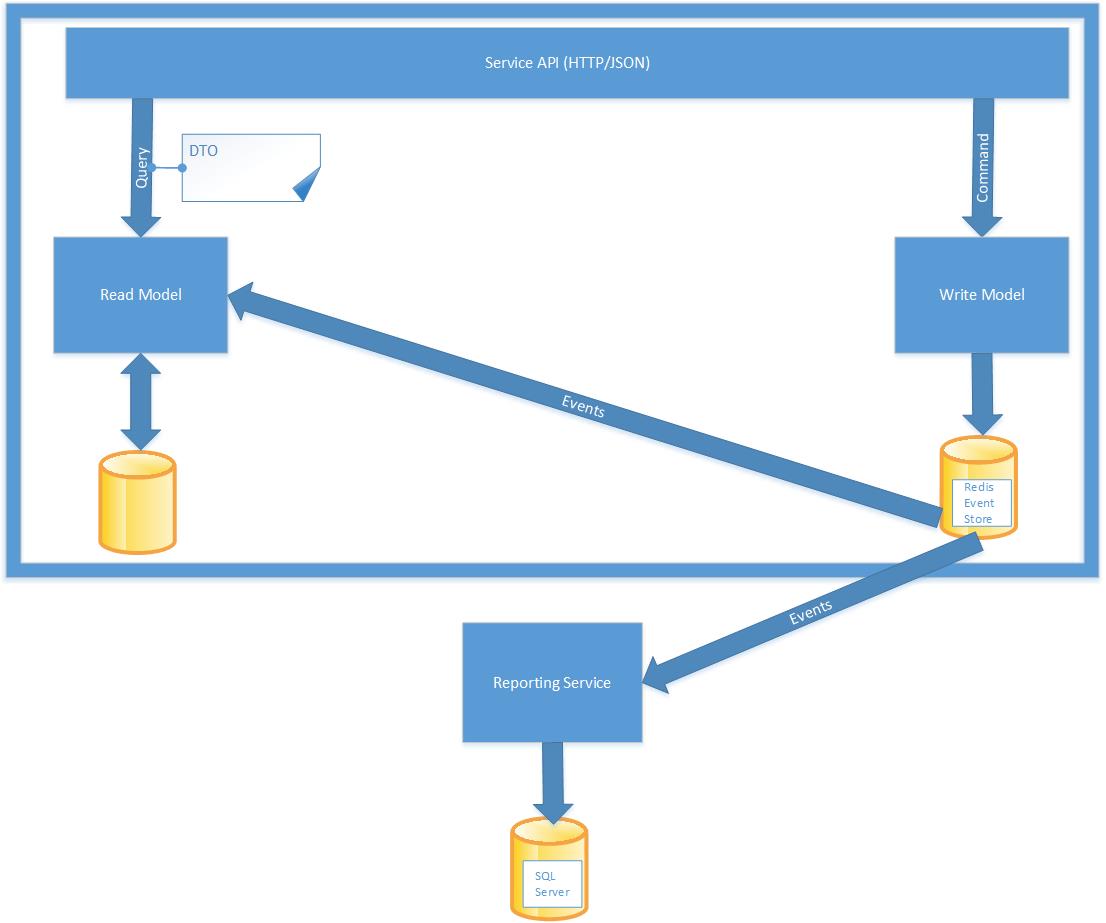
Redis is the technology we chose for implementing the Event Store at Learning.com. Redis is uniquely positioned for this purpose at our company as it offers very fast write performance, we are already using it as an integral part of our infrastructure so there is little additional cost for setting up new infrastructure, and it has built in pub/sub capability that can be used to publish events when data is written to the event store. For most materialized views, SQL Server is used as the data store because it is much better suited for ad hoc queries and data aggregation, and our development teams are already very familiar with it.
One possible criticism of this structure is that it seems like we may be duplicating data in the event store and in SQL Server. This is not the case however. In general, materialized views stored in SQL will only contain a subset of the data contained in the event store and that data will generally reflect the current state of the domain object. It will also be stored and aggregated in different ways to make it suitable for a specific purpose such as reporting. The event store also stores the entire history of a domain object in an audit log. This means that data stored in the event store can be “replayed” and projected to any other materialized view in the future, which is not true of data stored in SQL server for use in a specific view.
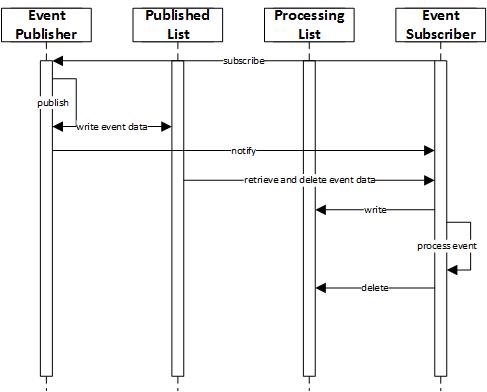
While Redis provides pub/sub capability, it is very basic. Event data is not stored internally by Redis so there is potential for data loss if subscribers are not listening for events. Therefore, steps must be taken to create a reliable queue to prevent data loss. The Redis documentation provides a pattern for creating such a reliable queue and this pattern is implemented in the Learning.EventStore library that we developed and use in all of our event driven services. The steps in publishing and consuming an event using the reliable queue are as follows:
- An event subscriber registers itself in a Subscribers List in Redis.
- When an event is published, event data is written to a Published List for each subscriber and a Redis event is published in an atomic operation. The event does not contain any data itself, it is simply notifying subscribers that there is event data waiting to be processed in the Published List. If a subscriber goes down, data will continue to be written to it’s Published List and can be picked up and processed by the subscriber once it comes back up.
- When a subscriber receives an event notification, it pops the event data from the Published List and pushes it to another Processing List in an atomic operation using the RPOPLPUSH command. This makes it possible to have multiple instances of a subscriber running, but ensures that only one of them will actually pick up the event data and process it. All instances will receive the event notification, but only one of them can pick up the event data and process it.
- Once processing is complete, event data is removed from the Processing List. If an error is encountered during processing, data remains in the Processing List and processing can be retried at a later time.
Data Architecture
The fundamental primitive in the EventStore is a domain object or Aggregate. Going back to the example above this would be something like an Order. The state of the Aggregate object is stored as a series of events. For example, there may be something like OrderCreated, QuantityChanged, OrderDeleted, etc.
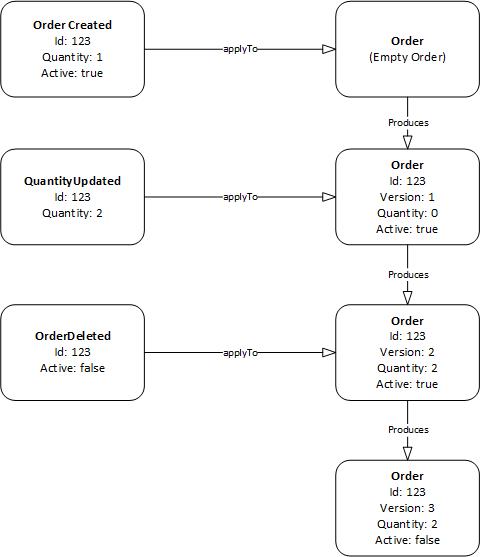
Within the event store, data is stored using a combination of data types offered by Redis:
- A Redis List stores the stream of events for an Aggregate
- Redis Hashes store the actual data associated with each event.
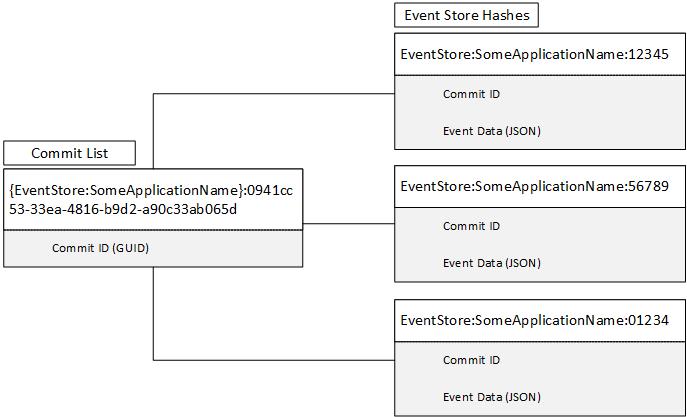
Each Aggregate receives a unique Aggregate ID in the form of a GUID. Each Aggregate then has a Commit List associated with it that is keyed off of the unique Aggregate ID. Each event that is stored for a particular Aggregate recieves a unique Commit ID. The Commit List for the Aggregate simply stores all of the Commit IDs associated with the Aggregate in the order that the were created. A Redis List is used for this because it maintains the order of the values as they are inserted and adding values to the end of a list is very fast as it is an O(1) operation.
For each Commit ID within the Commit List, there is a corresponding entry in a Redis Hash that uses the Commit ID as the key and stores the JSON event data as the value. Retrieving a single entry for a Hash is also a fast O(1) operation. In order to retrieve all events for an Aggregate, the entire Commit List can be retrieved using the Redis LRANGE. The list can then be itereated through and an HGET command issued to retrieve the data for each event. We use a CRC32 hash of the Commit ID and a modulo operation to partition the event data into multiple Redis Hashes.
private static string CalculatePartition(string commitId)
{
var bytes = Encoding.UTF8.GetBytes(commitId);
var hash = Crc32Algorithm.Compute(bytes);
var partition = hash % 655360;
return partition.ToString();
}
There are a couple of reasons for this:
- It ensures that data is evenly spread across the Redis Cluster.
- Redis stores small hashes in a more memory efficient way so it is better to have many small hashes than it is to have one large one for each event store.
Conclusion
When building a microservices based system, one of the core problems that must be addressed is how to share data between services while maintaining availability and consistency. Using an event-driven architecture allows services to remain highly decoupled while allowing data to be used in new and novel ways in the future that cannot be anticipated now and without the need to make sweeping changes to the existing system. Event Sourcing is a pattern for implementing an event-driven system that offers atomic operations in a distributed system without the need for expensive and complicated distributed transactions. Redis is a great technology for implementing Event Sourcing because it is already in use in many organizations, offers outstanding performance, and has built in pub/sub functionality. Thanks for reading, and look for a future post where we’ll dive into building an event-driven service using our Learning.EventStore library.
Originally posted on the Learning.com tech blog